En esta sección estudiaremos dos modelos fundamentales de aprendizaje supervisado: la regresión lineal, utilizada para variables de respuesta cuantitativas, y la regresión logística, empleada cuando la respuesta es categórica. Ambos modelos pueden ser formulados como problemas de optimización, lo que permite aplicar los conceptos vistos en el capítulo anterior. Para ambos modelos, analizaremos su formulación probabilística, las características del problema y los métodos de resolución más utilizados.
Durante este capítulo, consideraremos \(\XX=(X_1,\ldots,X_p)\in\RR^p\) un conjunto de variables predictoras y \(Y\in\RR\) una variable respuesta. Además, vamos a suponer que la distribución condicional de \(Y|\XX\) depende de un vector de parámetros \(\bftheta\in\RR^q\).
Para un conjunto de datos \(\{(\xx_i,y_i)\}_{i=1}^n\), denotamos \(X\in\RR^{n\times p}\) la matriz de predictoras y \(\yy\in\RR^n\) el vector de respuestas.
En lo que sigue, vamos a trabajar sin intercepto; es decir, consideraremos la relación lineal \(\bftheta^\top\XX\). Luego, si se necesitara un intercepto \(\theta_0\), los resultados se adaptan de forma directa reemplazando la matriz de datos \(X\) por la matriz ampliada \[
\widetilde{X}=\begin{pmatrix}\mathbf{1} & X\end{pmatrix}\in\RR^{n\times (p+1)}.
\]
Además, denotamos \(\mathbb{P}(A)\) la probabilidad de que ocurra un suceso \(A\), mientras que \(\media\left[Z\right]\) representa el valor esperado de la variable aleatoria \(Z\).
La tarea de obtener un estimador \(\hat{\bftheta}\) de \(\bftheta\) puede ser formulada a través de un problema de optimización de la forma \[
\begin{array}{ll}
\text{minimizar } & J(\bftheta),
\end{array}
\tag{1}
\]
en principio sin restricciones. Aquí, la función objetivo \(J:\RR^q\to\RR\), conocida como función de pérdida, mide que tan bien los parámetros \(\bftheta\) se ajustan a los datos observados. El punto óptimo del problema es el estimador buscado, por lo cual de ahora en adelante haremos la siguiente distinción:
Importante
Denotaremos por \(\bftheta^\star\) el valor verdadero del parámetro, mientras que \(\hat{\bftheta}\) será el estimador obtenido; es decir, \(\hat{\bftheta}\) es el punto óptimo del problema de optimización (1).
Bajo la suposición de que los datos son i.i.d. (independientes e idénticamente distribuidos), con distribución de densidad condicional \(p(y|\xx; \bftheta)\), una estrategia para formular \(J(\bftheta)\) es el principio de máxima verosimilitud, que consiste en elegir \(\hat{\bftheta}\) de manera tal que se maximice la función de verosimilitud
La función \(L(\bftheta)\) mide la compatibilidad de los datos con el modelo \(p(y|\xx; \bftheta)\) para un valor de \(\bftheta\) dado. En general, es más conveniente utilizar el logaritmo de la verosimilitud: \[
\ell(\bftheta):=\log L(\bftheta)=\sum_{i=1}^n\log p(y_i|\xx_i; \bftheta).
\tag{2}
\]
Luego, la definición de \(J(\bftheta)\) dependerá del problema específico. En general, tiene la forma \[
J(\bftheta)=\sum_{i=1}^n\text{loss}\,(y_i,f(\xx_i;\bftheta)),
\] donde \(\text{loss}:\RR\times\RR\to\RR_0^+\) mide el error entre el valor observado de la variable respuesta y el valor estimado por el modelo \(\hat{y}_i=f(\xx_i;\bftheta)\).
El conjunto de parámetros del modelo de regresión lineal es \(\bftheta\in\RR^p\), mientras que \(\varepsilon\in\RR\) es un término de error que captura efectos no modelados (como características omitidas o ruido aleatorio). Podemos escribir el modelo de forma abreviada como \[
Y = \bftheta^\top \XX + \varepsilon.
\]
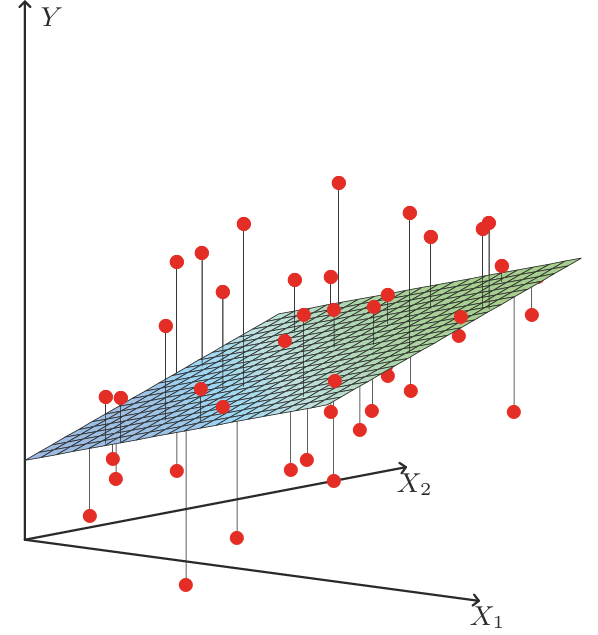
Figura 1. Interpretación geométrica del modelo de regresión lineal en \(\RR^2\). Los puntos ajustados están determinados por las proyecciones sobre el plano \(\hat{y}=\theta_1 x_1+\theta_2 x_2\) (más intercepto).
El supuesto \(\varepsilon\sim \calN(0,\sigma^2)\) significa que la función de densidad de la variable aleatoria \(\varepsilon\) es \[
p(\varepsilon) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{\varepsilon^2}{2 \sigma^2}\right).
\]
Distribución condicional
Dado \(\XX=\xx\), tenemos que \[
Y=\underbrace{\bftheta^\top\xx}_{\text{cte}}+\varepsilon.
\]
Por lo tanto, el supuesto \(\varepsilon\sim\calN(0,\sigma^2)\) implica que \[
Y|\XX=\xx\sim \calN(\bftheta^\top\xx,\sigma^2).
\]
Finalmente:
La función de densidad condicional de \(Y|\XX\) en el modelo de regresión lineal es \[
p(y |\xx; \bftheta) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{(y-\bftheta^\top \xx)^2}{2 \sigma^2}\right).
\]
Función de verosimilitud
Para un conjunto de datos \(\{\xx_i, y_i\}_{i=1}^n\) i.i.d., la función de verosimilitud es
Dado que es un problema de optimización sin restricciones con función objetivo convexa, la condición de optimalidad \(\nabla J(\bftheta)=\bfzero\) es suficiente y necesaria. Por lo tanto, tenemos que \[
\begin{align*}
\nabla J(\hat{\bftheta})&=\bfzero\\
X^\top X\hat{\bftheta}-X^\top\yy&=\bfzero\\
X^\top X\hat{\bftheta} &=X^\top\yy\\
\hat{\bftheta}&=X^{+}\yy.
\end{align*}
\]
Si \(X\) es de rango completo, entonces \[
\hat{\bftheta}=(X^\top X)^{-1}X^\top\yy
\]
El vector de valores ajustados \(\hat{\yy}\in\RR^n\) está dado por \[
\hat{\yy}:=X\hat{\bftheta}.
\]
Observar que, si \(X\) es de rango completo, entonces \(\hat{\yy}=X(X^\top X)^{-1}X^\top\yy\). Esto significa que \(\hat{\yy}\) es la proyección de \(\yy\) sobre el espacio columna de \(X\).
Algoritmo LMS
La aplicación del método de descenso por gradiente al problema de optimización en regresión lineal da lugar a lo que se denomina algoritmo LMS (least mean squares). La regla de actualización es \[
\bftheta_{t+1}:=\bftheta_t-\eta \nabla J(\bftheta_t),\qquad\eta>0.
\]
Luego, debemos sustituir el gradiente por su expresión \(\nabla J(\bftheta_t) = X^\top X\bftheta_t-X^\top\yy\). Esta regla de actualización tambien se conoce como regla de aprendizaje Widrow-Hoff.
Algoritmo LMS
Dado un parámetro inicial\(\bftheta_0\in\RR^{p}\) y una tasa de aprendizaje\(\eta>0\):
En el algoritmo anterior se está trabajando con todas las observaciones a la vez en cada paso de actualización, por lo que se trata de un descenso de gradiente por lotes. Esta estrategia asegura una actualización estable del parámetro \(\bftheta\), aunque puede ser costosa si el número de observaciones es muy grande.
Por supuesto, como vimos en C1-S5, como alternativa podemos usar descenso de gradiente estocástico o mini-batch. Para ello, notar que para una observación \((\xx_i,y_i)\), la función de pérdida resulta \[
\text{loss}\,(y_i,f(\xx_i;\bftheta))=\frac{1}{2}(y_i-\bftheta^\top\xx_i)^2,
\] tal que \[
\nabla_{\bftheta} \text{loss}\,(y_i,f(\xx_i;\bftheta)) = -(y_i-\bftheta^\top\xx_i)\,\xx_i.
\]
Algoritmo LMS estocástico
Dado un parámetro inicial\(\bftheta_0\in\RR^{p}\) y una tasa de aprendizaje\(\eta>0\):
repetir para \(t = 0,1,2,\dots\):
1° Elegir un índice \(i\) al azar de \(\{1,\dots,n\}\).
Observar que la magnitud de la actualización del algoritmo LMS estocástico es proporcional al término de error \((y_i - \bftheta_t^\top\xx_i)\). Si elegimos un ejemplo para el cual \(\bftheta_t^\top\xx_i\approx y_i\), entonces el cambio en el parámetro será mínimo. Esto puede activar prematuramente el criterio de parada basado en la magnitud del gradiente, por lo cual para para evitar detener el algoritmo demasiado pronto, suele ser recomendable basar el criterio de parada en el promedio del error sobre un conjunto de observaciones. También se puede imponer un número mínimo de iteraciones para asegurar que el algoritmo recorra suficientes ejemplos y aprenda de manera estable.
Ejemplo 1 Regresión lineal en datos California Housing
Utilizaremos el conjunto de datos de California Housing (disponible aquí), el cual consiste en 20640 observaciones con 8 variables predictoras que miden características de las viviendas y su entorno. La variable respuesta es el valor mediano de la vivienda en cada bloque censal, por lo que este problema es de regresión.
Ajustaremos un modelo de regresión lineal a los datos, evaluaremos el MSE en test y presentaremos los coeficientes estimados del modelo.
import numpy as npfrom sklearn.datasets import fetch_california_housingfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_error# Datos:X, y = fetch_california_housing(return_X_y=True)scaler = StandardScaler()X = scaler.fit_transform(X)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Modelo:lr = LinearRegression()lr.fit(X_train, y_train)# Predicción y MSE:y_pred = lr.predict(X_test)mse_test = mean_squared_error(y_test, y_pred)# 📋:print(f"MSE en test: {mse_test:.3f}")print("Coeficientes estimados (θ̂):")for i, coef inenumerate(lr.coef_):print(f"θ_{i+1} = {coef:.3f}")
Hemos visto que el algoritmo LMS permite aproximar el estimador de mínimos cuadrados \(\hat{\bftheta}\) para el modelo de regresión lineal. Por supuesto, los resultados de convergencia vistos en C1-S5 para el método de descenso por gradiente son válidos.
No obstante, \(\hat{\bftheta}\) es un estimador del valor verdadero \(\bftheta^\star\), por lo que resulta relevante estudiar sus propiedades estadísticas, tales como consistencia, sesgo y varianza, para entender qué tan buena es la estimación \(\hat{\bftheta}\), incluso después de la convergencia del algoritmo LMS.
Importante
En base a lo descrito, es fundamental distinguir dos niveles de convergencia:
Convergencia estadística del estimador: se refiere al hecho de que el estimador \(\hat{\bftheta}_n\) converge en probabilidad al valor verdadero \(\bftheta^\star\). Simbólicamente: \[
\text{plim}_{n\to\infty}\hat{\bftheta}_n=\bftheta^\star\qquad (\hat{\bftheta}_n\xrightarrow{p}\bftheta^\star).
\]
Observar que escribimos \(\hat{\bftheta}_n\) para explicitar la dependencia del estimador respecto al tamaño muestral \(n\).
Convergencia computacional del algoritmo: se refiere a que la sucesión producida por un algoritmo iterativo (por ejemplo, descenso por gradiente) converge a \(\hat{\bftheta}\) (aquí no escribimos el subíndice porque \(n\) es fijo). Esto es: \[
\lim_{t\to\infty}\bftheta_t=\hat{\bftheta}\qquad(\bftheta_t\to\hat{\bftheta}).
\]
Ahora sí estamos en condiciones de revisar algunos resultados conocidos para el modelo de regresión lineal.
Convergencia estadística: para \(n>p\) y bajo los supuestos clásicos de \[
\begin{array}{cl}
\{(\xx_i,y_i)\}_{i=1}^n\text{ i.i.d.},\; \media\left[\varepsilon_i\mid\xx_i\right]=0 & \text{(Exogeneidad)} \\[2pt]
\media\left[\varepsilon_i^2\mid \xx_i\right]=\sigma^2<\infty,\;\media\left[\varepsilon_i^4\right] & \text{(Momentos)} \\
\frac{1}{n}X^\top X\xrightarrow{p}\Sigma_{X}\succ 0 & \text{(Diseño bien condicionado)}
\end{array}
\] se verifica \[
\hat{\bftheta}_n\xrightarrow{p}\bftheta^\star\qquad\text{y}\qquad\sqrt{n}\, (\hat{\bftheta}_n-\bftheta^\star)\xrightarrow{d}\mathcal{N}(0,\sigma^2\Sigma_X^{-1}).
\]
Convergencia computacional: sean \(\lambda_{\text{min}},\lambda_{\text{max}}>0\) autovalores de \(X^\top X\). Si \(0<\eta<2/\lambda_{\text{max}}\), entonces \[
\bftheta_t\to\hat{\bftheta}\qquad\text{y}\qquad\|\bftheta_t-\hat{\bftheta}\|_2\leq\rho^t\|\bftheta_0-\hat{\bftheta}\|_2,
\] con \(\rho=\max\left\{|1-\eta\lambda_{\text{min}}|,|1-\eta\lambda_{\text{max}}|\right\}\).
Regresión logística
Consideremos ahora un problema de clasificación binaria, con variable respuesta \(Y\in\{0,1\}\).
Por ejemplo, si estamos tratando de construir un clasificador de spam para correos electrónicos, entonces una observación \(\xx\) contendrá características de un correo electrónico, mientras que su etiqueta \(y\) será 1 si es spam o 0 en caso contrario.
Podríamos abordar el problema de clasificación ignorando el hecho de que \(y\) toma valores discretos y usar el método de regresión lineal. Sin embargo, no tendría sentido que la predicción para un valor de \(\xx\) sea un valor fuera del rango de 0 y 1. Para resolver este problema, podemos utilizar la función logística.
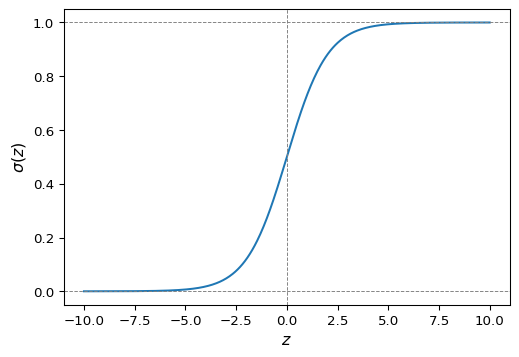
Función logística
Para \(z\in\RR\), se define la función logística o función sigmoide\(\sigma:\RR\to\RR\) mediante \[
\sigma(z) := \frac{1}{1 + e^{-z}} = \frac{e^z}{1+e^z}.
\]
Algunas características son:
El conjunto imagen es \(\sigma(\RR)=(0,1)\).
\(\sigma(0) = 0.5\)
\(\displaystyle\lim_{z\to -\infty}\sigma(z)=0\) y \(\displaystyle\lim_{z\to\infty} \sigma(z)=1\).
\(\sigma'(z)=\sigma(z)(1-\sigma(z))\).
Ya estamos en condiciones de configurar el modelo de regresión logística. Para ello, primero definimos la función \(h_{\bftheta}:\RR^p\to\RR\) como \[
h_\bftheta(\xx) := \sigma(\bftheta^\top \xx) = \frac{1}{1 + e^{-\bftheta^\top \xx}}.
\]
Bajo el modelo de regresión logística, resulta \[
Y|\XX=\xx\sim\text{Binom}(1,h_{\bftheta}(\xx)),
\]
de manera tal que \[
\begin{align*}
p(y \mid \xx; \bftheta)&=(h_{\bftheta}(\xx))^y(1-h_{\bftheta}(\xx))^{1-y} \\[2pt]
&=\left( \frac{e^{\bftheta^\top\xx}}{1 + e^{\bftheta^\top \xx}} \right)^y\,\left( 1-\frac{e^{\bftheta^\top\xx}}{1 + e^{\bftheta^\top \xx}} \right)^{1-y} \\[3pt]
&=\left( \frac{e^{\bftheta^\top\xx}}{1 + e^{\bftheta^\top \xx}} \right)^y\,\left( \frac{1}{1 + e^{\bftheta^\top \xx}} \right)^{1-y} \\
&=\frac{e^{\bftheta^\top\xx\, y}}{1+e^{\bftheta^\top\xx}}.
\end{align*}
\]
Finalmente:
La función de probabilidad condicional de \(Y|\XX\) en el modelo de regresión logística es \[
p(y \mid \xx; \bftheta) = \frac{e^{\bftheta^\top\xx\, y}}{1+e^{\bftheta^\top\xx}}.
\]
Función de verosimilitud
Para un conjunto de datos \(\{\xx_i, y_i\}_{i=1}^n\) i.i.d., la función de verosimilitud es
En regresión logística, maximizar \(\ell(\theta)\) es equivalente a minimizar \[
J(\bftheta)=-\sum_{i=1}^{n}\left[y_i\log(\hat{y}_i)+(1-y_i)\log(1-\hat{y}_i)\right],
\tag{3}
\]
con \[
\hat{y}_i:=h_{\bftheta}(\xx_i)=\frac{1}{1+e^{-\bftheta^\top\xx_i}}.
\]
La función \(J(\theta)\) en (3), conocida como entropía cruzada, es la forma habitual de expresar la función de pérdida en problemas de clasificación binaria. Mide la disimilaridad entre las etiquetas reales \(y_i\) y las probabilidades \(\hat{y}_i\) predichas por el modelo.
📝
Verifique que se cumple \(J(\bftheta)=-\ell(\bftheta)\).
Optimalidad
Vamos a analizar el problema \[
\begin{array}{ll}
\text{minimizar} & \sum_{i=1}^n\left[\log(1+e^{\bftheta^\top\xx_i})-\bftheta^\top\xx_i y_i\right].
\end{array}
\tag{4}
\]
La función objetivo es convexa. Por lo tanto, la condición de optimalidad \(\nabla J(\bftheta)=\bfzero\) es una condición necesaria y suficiente para el punto óptimo \(\hat{\bftheta}\).
📝
Justifique la convexidad de la función objetivo en (4) y comente sobre la existencia de solución.
La forma matricial de la función objetivo es \[
J(\bftheta)=\mathbf{1}^\top\log\left(1+e^{X\bftheta}\right)-\yy^\top X \bftheta,
\]
donde las operaciones \(\log\) y \(e\) se aplican elemento a elemento; esto es, \(\zz=\log\left(1+e^{X\bftheta}\right)\in\RR^n\) cumple \(\zz_i=\log(1+e^{\bftheta^\top\xx_i})\). Se tiene que
donde \(\hat{\yy}\in\RR^n\) es el vector de valores ajustados dado por \[
\hat{\yy} := (h(\bftheta^\top\xx_1),\ldots,h(\bftheta^\top\xx_n))^\top=\sigma(X\bftheta).
\]
La expresión (5) muestra que \(\nabla J(\bftheta)\) depende de \(\bftheta\) de forma no lineal. Por lo tanto, no es posible obtener una solución explícita de \(\nabla J(\hat{\bftheta})=\bfzero\) y la única opción es recurrir a métodos iterativos para aproximar \(\hat{\bftheta}\).
Aplicación de descenso por gradiente
Algoritmo de descenso por gradiente para regresión logística
Dado un parámetro inicial\(\bftheta_0\in\RR^{p}\) y una tasa de aprendizaje\(\eta>0\):
Por último, obtengamos el algoritmo de descenso por gradiente estocástico. Para una observación \((\xx_i,y_i)\) se tiene \[
J(\bftheta)=\log(1+e^{\bftheta^\top\xx_i})-\bftheta^\top\xx_iy_i,
\]
tal que \[
\nabla J(\bftheta)=\frac{e^{\bftheta^\top\xx_i}}{1+e^{\bftheta^\top\xx_i}}\xx_i-\xx_i y_i=\xx_i (h_{\bftheta}(\xx_i)-y_i)=-\xx_i(y_i-h_{\bftheta}(\xx_i)).
\]
Algoritmo de descenso por gradiente estocástico para regresión logística
Dado un parámetro inicial\(\bftheta_0\in\RR^{p}\) y una tasa de aprendizaje\(\eta>0\):
repetir para \(t = 0,1,2,\ldots\):
1° Elegir un índice \(i\) al azar de \(\{1,\dots,n\}\).
El conjunto de datos de Breast Cancer (disponible aquí) contiene información de tumores de mama. Consta de 569 observaciones y 30 variables predictoras. La variable respuesta indica el tipo de tumor (0 para benigno y 1 para maligno), lo que convierte este problema en una tarea de clasificación binaria.
Ajustaremos un modelo de regresión lineal a los datos, evaluaremos el accuracy en test y presentaremos los coeficientes estimados del modelo.
import numpy as npfrom sklearn.datasets import load_breast_cancerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# Datos:X, y = load_breast_cancer(return_X_y=True)scaler = StandardScaler()X = scaler.fit_transform(X)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Modelo:logreg = LogisticRegression(max_iter=1000)logreg.fit(X_train, y_train)# Predicción y accuracy:y_pred = logreg.predict(X_test)acc_test = accuracy_score(y_test, y_pred)# 📋:print(f"Accuracy en test: {acc_test:.3f}")print("Coeficientes estimados (θ̂):")for i, coef inenumerate(logreg.coef_[0]):print(f"θ_{i+1} = {coef:.3f}")
Para el caso de regresión logística, algunos resultados importantes son:
Convergencia estadística: bajo supuestos clásicos, tales como \[
\begin{array}{cl}
\{(\xx_i,y_i)\}_{i=1}^n \text{ i.i.d.} & (\text{Independencia e idéntica distribución}) \\[1ex]
0<\mathbb{P}(Y_i=1\mid \xx_i)<1 & \text{(No separabilidad)}\\[1ex]
\mathbb{E}[\|\xx_i\|^2]<\infty & \text{(Momentos finitos)}\\[1ex]
I(\bftheta^\star) = \media\left[h_{\bftheta}(\XX)(1-h_{\bftheta}(\XX))\,\XX\XX^\top\right] \succ 0 & \text{(Información de Fisher definida positiva)}
\end{array}
\]
se verifica \[
\hat{\bftheta}_n\xrightarrow{p}\bftheta^\star\qquad\text{y}\qquad\sqrt{n}\, (\hat{\bftheta}_n-\bftheta^\star)\xrightarrow{d}\mathcal{N}(0,\mathcal{I}(\bftheta^\star)^{-1}).
\]
Convergencia computacional: como \(J\) es convexa y \(L\)-suave con \[
L\leq\frac{\lambda_{\text{max}(X^\top X)}}{4},
\] el método de descenso por gradiente verifica \[
J(\bftheta_t)\to\ J(\hat{\bftheta}).
\]
Para finalizar esta sección, comparemos los factores en la actualización del método de descenso por gradiente estocástico para los modelos vistos:
En ambos casos, la actualización depende del error entre el valor observado y la predicción del modelo: \[
y_i-\hat{y}_i,
\] donde \(\hat{y}_i=\bftheta^\top\xx_i\) para regresión lineal y \(\hat{y}_i=\displaystyle\frac{e^{\bftheta^\top\xx_i}}{1+e^{\bftheta^\top \xx_i}}\) para regresión logística.
Esta estructura común refleja la idea de ajustar los parámetros en función de la discrepancia entre observaciones y predicciones, lo cual generalizaremos en la próxima sección cuando tratemos los modelos lineales generalizados.
Actividades
✏️ Conceptuales
Análisis de residuos.
Transformaciones en regresión.
Referencias
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction (2nd ed.). Springer.
Ng, A. Apuntes del curso Stanford CS229: Machine Learning. Disponible aquí.